Python dasturlash tili kutubxonalari bilan sun’iy intellekt tizimlarini ishlab chiqish. Pandas kutubxonasi











![“data” nomli Series ma’lumotlar tuzilmasining qandaydir oraliqdagi
elementlari kerak bo’lsa data[a:b] shaklda murojaat qilamiz.
Series ma’lumotlar tuzilmasining elementlarini filtrlashning quyidagi
usullari mavjud.
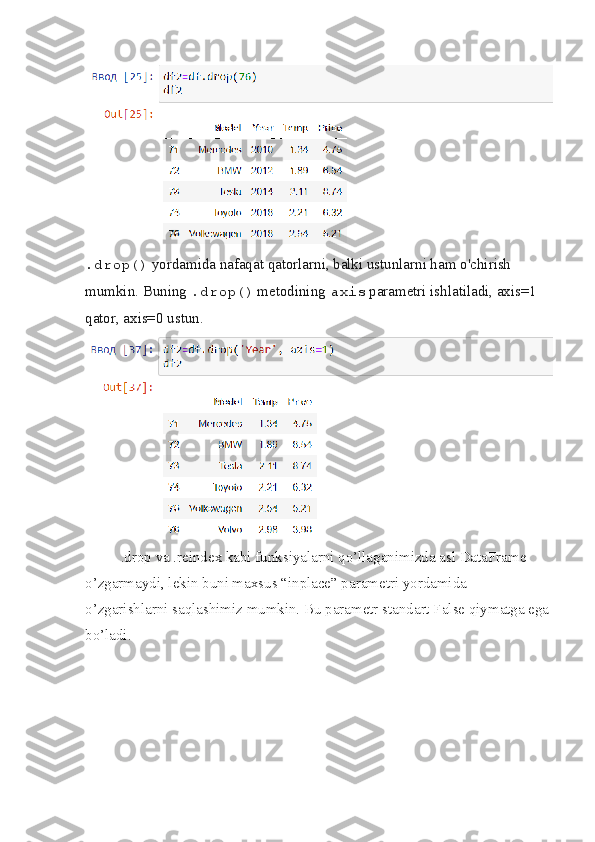
2) DataFrameda ma’lumotlar tuzilmasida elementlarni tanlash.
“df” nomli yangi DataFrame ma’lumotlar tuzilmasini yaratib olamiz.](/data/documents/8d849656-3466-42de-8bd5-3d46d5f1bac2/page_13.png)










Python dasturlash tili kutubxonalari bilan sun’iy intellekt tizimlarini ishlab chiqish. Pandas kutubxonasi . Reja: 1. Pandas 2. Series ma’lumotlar tuzilmasi 3. DataFrame ma’lumotlar tuzilmasi
Pandas - bu ochiq manbali kutubxona bo'lib, u asosan aloqador yoki etiketli ma'lumotlar bilan oson va intuitiv tarzda ishlash uchun yaratilgan. U turli xil ma'lumotlar tuzilmalari va raqamli ma'lumotlar va vaqt seriyalarini manipulyatsiya qilish uchun operatsiyalarni taqdim etadi. Bu kutubxona NumPy kutubxonasi ustiga qurilgan. Pandas tez va u foydalanuvchilar uchun yuqori unumdorlikka ega. Pandas kutubxonasi afzalliklari: Ma'lumotlarni manipulyatsiya qilish va tahlil qilish uchun tez va samarali. Turli fayl ob'ektlaridan ma'lumotlarni yuklash mumkin. Suzuvchi nuqtada etishmayotgan ma'lumotlarni (NaN sifatida ko'rsatilgan) va suzuvchi nuqta ma'lumotlarini oson boshqarish Hajmi o'zgaruvchanligi: ustunlarni DataFrame va undan yuqori o'lchamli ob'ektlardan kiritish va o'chirish mumkin Ma'lumotlar to'plamini birlashtirish va qo'shish. Ma'lumotlar to'plamlarini moslashuvchan qayta shakllantirish va aylantirish Vaqt seriyali funksiyalarini ta'minlaydi. Ma'lumotlar to'plamlarida bo'lish va birlashtirish operatsiyalarini bajarish uchun funktsional imkoniyatlar mavjudligi. Pandasda ishlashning birinchi qadami uning Python papkasida o'rnatilgan yoki o'rnatilmaganligiga ishonch hosil qilishdir. Agar yo'q bo'lsa, biz uni tizimimizga pip buyrug'i yordamida o'rnatishimiz kerak: pip install pandas. Pandas tizimga o'rnatilgandan so'ng, kutubxonani import qilishingiz kerak: Import pandas as pd Pandas odatda ma'lumotlarni manipulyatsiya qilish uchun ikkita ma'lumotlar tuzilmasini taqdim etadilar, ular: Seriya
DataFrame Series ma’lumotlar tuzilmasi Series: Pandas Series - bu har qanday turdagi ma'lumotlarni (int, string, float, python ob'ektlari va boshqalar) saqlashga qodir bo'lgan bir o'lchovli etiketli massiv. Pandas kutubxonasidagi Series ma’lumotlar tuzilmasini Pythondagi oddiy kutubxonalardan farqlaridan biri ro’yhatdagi obyektlarga o’zimiz index berishimiz mumkin. Dastlab “object” nomli Series turidagi massiv yaratib, indexlarini o’zimiz beramiz. Obyekt ichidagi qiymatlarga indeks orqali murojaat qilamiz: Series obyektiga oid ba'zi parametrlar va metodlar: 1) values – obyekt qiymatlarini ekranga chiqaradi 2) hasnans – NaN qiymatlar bor yoki yo’qligini tekshiradi. 3) dtype – qiymatlarning ma’lumot turini tekshiradi
4) is_unique – qiymatlar takrorlanmas ekanligini tekshiradi 5) shape – Series hajmini aniqlaydi 6) max va min – qiymatlarning maksimum va minimumini aniqlaydi. DataFrame ma’lumotlar tuzilmasi Pandas DataFrame 2 o lchovli ma lumotlar strukturasi bo lib, 2 ʻ ʼ ʻ o lchovli massiv yoki satr va ustunli jadval kabi o’rinishda bo’ladi. Pandas ʻ DataFrame uchta asosiy komponentdan iborat: ma'lumotlar , qatorlar va ustunlar .
Pandas DataFrame mavjud xotiradan ma'lumotlar to'plamini yuklash orqali yaratiladi, fayllar SQL ma'lumotlar bazasi, CSV fayli va Excel fayli bo'lishi mumkin. Pandas DataFrame ro yxatlar, lug atlar va hokazolardan ʻ ʻ yaratilishi mumkin. DataFrame yaratishning bir nechta usuli bor va bulardan eng osoni qiymatlari bir hil uzunlikdagi ro'yxatdan iborat lug'at orqali yaratish. Dastlab “data” nomli lug’at yaratib olamiz pd.DataFrame() buyrug’i orqali lug’atni DataFramega o’tkazamiz