Daslabki ma’lumotlarga ishlov berish. Ma’lumotlar tahlili. Ma’lumotlarni tayyorlash.








Daslabki ma’lumotlarga ishlov berish. Ma’lumotlar tahlili. Ma’lumotlarni tayyorlash. Reja: 1. Fayldan ma’lumotlarni o’qish 2. Fayllarga ma’lumotlarni yozish. 3. HDF5 formati.
1. Fayllar bilan ishlash. 1.1 Fayldan ma’lumotlarni o’qish. Pandas kutubxonasi fayllar bilan ishlaydigan bir nechta funksiyalardan iborat . read_csv - vergul bilan ajratilgan jadval fayllarni o'qish uchun read_table - probel (bo'sh joy) bilan ajratilgan jadval fayllarni o'qish uchun read_excel - xls yoki xlsx formatidagi Excel fayllarni o'qish uchun read_clipboard - ko'chirilgan (xotiradagi) jadvalni o'qish read_hdf - HDF5 formatidagi fayllarni o'qish read_html - HTML (web) sahifadagi barcha jadvallarni o'qish read_json - JSON ma'lumotlarni o'qish read_pickle - pickle formatidagi fayllarni o'qish read_sql - SQL query dan qaytgan ma'lumotlarni o'qish (SQLAlchemy bilan ishlayd) Yuqoridagi funksiyalarning deyarlari barchasining ishlashi juda o'xshash, muhimi, to'g'ri formatdagi faylni ko'rsatish va turli qo'shimcha parametrlardan foydalangan xolda jadvalni to'g'ri yaratib olish. Fayl kompyuterdagi yoki onlinedagi fayl bo'lishi mumkin. Dars davomida Githubda joylashgan turli fayllardan foydalanamiz. Siz kerakli faylni kompyuterga yuklab olib, Jupyter Notebookda ochishingiz mumkin . Agar kerakli fayl Jupyter Notebook fayli joylashgan papkada bo’lsa shunchaki nomini yozamiz.
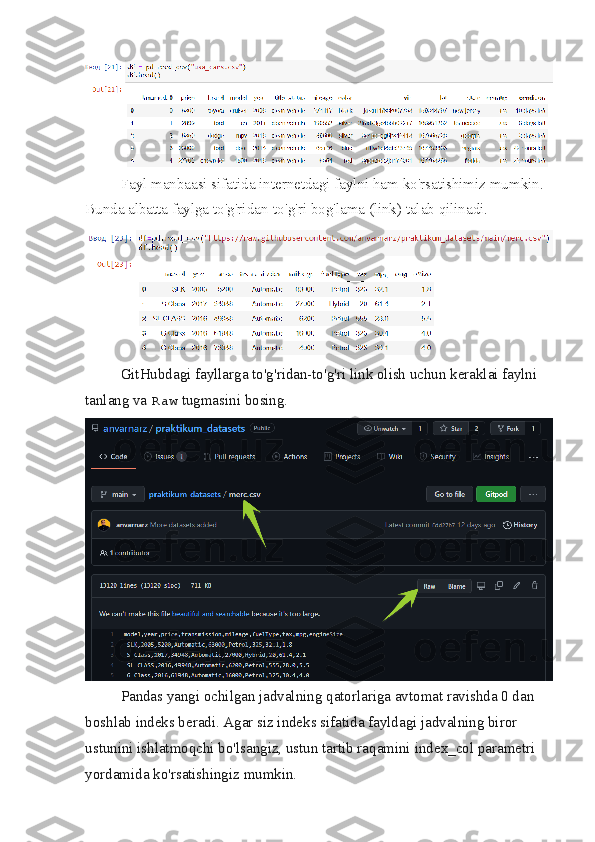
Fayl manbaasi sifatida internetdagi faylni ham ko'rsatishimiz mumkin. Bunda albatta faylga to'g'ridan-to'g'ri bog'lama (link) talab qilinadi. GitHubdagi fayllarga to'g'ridan-to'g'ri link olish uchun keraklai faylni tanlang va Raw tugmasini bosing. Pandas yangi ochilgan jadvalning qatorlariga avtomat ravishda 0 dan boshlab indeks beradi. Agar siz indeks sifatida fayldagi jadvalning biror ustunini ishlatmoqchi bo'lsangiz, ustun tartib raqamini index_col parametri yordamida ko'rsatishingiz mumkin.
.nrows parametri yordamida jadvaldan faqatgina sanoqli qatorlarni o'qish mumkin. Bu katta jadvallar bilan ishlash uchun qulay. Pandasda fayllarni o'qishda 50 ga yaqin parametrlarni ko'rsatish mumkin. To'liq ro'yxat bilan quyidagi sayt orqali tanishish mumkin: pandas.pydata.org. 1.2 Fayllarga ma’lumotlarni yozish. Fayllarga ma’lumotlarni yozish uchun dastlab birorta faylni chaqirib olamiz.
Faylni chaqirib olgandan so’ng “to” buyrug’i orqali biror faylga yozamiz. Series obyektini ham faylga yozishimiz mumkin. Dastlab, Series obyektini yaratib olamiz. Series obyektini fayldan o’qilganda avtomatik DataFramega aylanadi, buni o’zgartirish uchun squeeze parametridan foydalanamiz.